I’ve been holding off on this topic for a few weeks now, but I think it’s finally time to talk about Atlassian’s recent cloud outage, why it happened, and – more importantly – what Atlassian is doing to prevent this from happening. Some of you were not shy about commenting that even though I was criticizing Atlassian’s direction on Data Center, I was notably mute on that subject until now.

The reason, though, was simple. Before I wrote about the Outage, I wanted to have all the facts. Unfortunately, this meant I had to wait until Atlassian released their “Post-Incident Review” on the topic, which Atlassian’s CTO had already promised on 12 Apr. Atlassian finally released this document to us this past Friday, 29 Apr, and there are more than a few tidbits to glean from it. The entire document is roughly five times the size I try to hit for my posts, so they went into a good amount of detail. So, let’s dig into this.
Severity and Scale
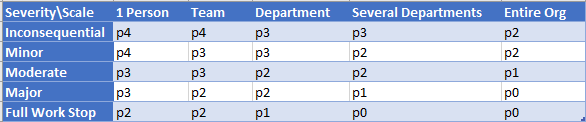
So, let’s first talk about two things that determine how bad an event was – Severity, which measures how impacted are users, and Scale, which measures how many users are impacted. I usually use both to judge any outage or potential Outage of service by putting these into a matrix. This will give me an idea of what the Priority should be using the p-scale, which goes from p0 (Drop everything else, top Priority) to p4 (Trivial task).
So let’s talk about Scale first. During the event, Atlassian estimated that some 400 customers were impacted (per the blog post from Sri dated 12 Apr 2022). However, after the event, Atlassian came to a final number of 775 total customers impacted – nearly double their original estimate.
The problem here is that Atlassian accidentally deleted the entire Cloud Site, including all relevant contact records. So, they didn’t even have the contact information to reach out to people to see how impacted they were. Therefore, part of the recovery process included figuring out how bad the problem was.
As far as severity, it isn’t good. Imagine it’s your entire Jira and Confluence instance that is offline. How much work could your teams get done? How frantic would you be? Now imagine that, times 700. That’s where Atlassian was.
So, what happened
Root Causes
First, let me recount a story. In 1999, NASA lost a Mars probe that was supposed to Orbit the planet and send back weather information. Instead, it hit the Martian atmosphere full force and broke apart. The reason for this dramatic miscalculation? The Probe – which Lockheed Martin Astronautics built to use Imperial measurements – was instead given Metric units by Nasa’s JPL. Unfortunately, the two teams failed to discuss the units they’d use, and the Probe’s computer took whatever numbers the Engineers gave it and assumed it was correct.
I remember discussing this event as a cautionary tale during some of my case studies at University. This was meant to teach us a few lessons. First, never assume you are working with the same units, and label what you have. Second – especially as computer and software engineers – never trust input from your users.
What does this have to do with the event we are talking about now? Well, they both have a similar root cause.
As part of Atlassian’s acquisition of Insight, the product was rolled into Jira itself, making the old legacy app defunct. So Atlassian set about a maintenance task to remove the App from a number of customers who still had it on their Jira Cloud instances. Now, the team requesting the deletion was not the team that would perform the deletion. This is where the problem came in.
The team requesting the deletion gave a list of ID numbers for Cloud Sites that still had the legacy App. However, the group that was performing the deletion was expecting the list to contain the ID of the App itself – not the Cloud Site.
The API call they were to make could accept either as an input. So if the API got a Site ID, it would delete the site, and if it got an App ID, it would just delete that App, leaving the site still intact. Furthermore, this API assumed the input was correct and gave no warning that you were about to delete a Site.
So again, we have two groups, working off different assumptions and a computer system that accepted whatever was given as truth. The result was the deletion of 883 sites belonging to 775 customers that took 23 minutes to complete. This caused the following Cloud products to no longer be available to impacted customers: Jira, Confluence, Atlassian Access, Opsgenie, and Statuspage.
Now – Atlassian provided several failings that led to the initial incident. They listed the Communication Gap between the two teams that caused the wrong kind of ID to be listed. They also included that the API included an insufficient warning that you were deleting a Site rather than an App. Personally – I would go a step further in saying that the two should be on entirely different API calls so that the process would have failed when given the Site ID, but that’s just me.
Timeline of Events
Day 0 – 5 Apr 2022
Atlassian started the process of calling the API via a script (henceforth “The Script”) at 7:38 UTC and got the first ticket about a problem at 7:46 UTC. Because this was a called deletion – their internal tooling couldn’t detect there was a problem. The Script was completed at 8:01 UTC, and Atlassian realized there was a significant problem and triggered their major incident management process at 8:17 UTC.
It should be noted this did happen to coincide with Team ’22, which also started 5 Apr 2022.
By 8:22 UTC, Atlassian had escalated the incident to Critical, and at 8:53 UTC, Atlassian confirmed The Script was related to the Outage. However, it took them another 2 hours and 45 minutes to complete the triage and realize how complex the restoration would be. At that point, Atlassian escalated the incident again to its highest severity.
By 6 Apr 2022, Atlassian had done enough investigation to realize this wasn’t going to be easy to resolve. They had built their tooling to recover a single mistakenly deleted site – which itself was a long process that required multiple teams. Now they had hundreds of sites to recover and no tooling to handle this in batches. So Atlassian immediately began parallel work streams. One group was set to task to start restoring sites with the tooling they had, and another group was set to work creating tools to allow automatic restoration in batches.
Atlassian initially estimated that restoring one site at a time could take them upwards of three weeks to restore users, which caused outrage within the community. Therefore, on 9 Apr 2022, Atlassian came up with a new method that allowed them to streamline the restoration. However, the new process required a fair amount of retooling, overhead, and duplicate verification work. However, the time saved was deemed worthwhile, and Atlassian used it for approximately 47% of the restored sites, with the last site restored on 18 Apr 2022.
Now, Atlassian realizes and admits they got a few things wrong in this incident. One of the things I want to note is they didn’t do a good job of communicating publically. They waited until they had a complete picture to release a public statement rather than release an immediate statement and being transparent about what they did and did not know. As readers will well know, I’ve had questions about Atlassian’s transparency as of late, so I’m happy to see Atlassian admitting they could do better here.
The people who would have been reading these are technical contacts – people who know what it’s like to run services. Many of them likely ran Jira before migrating to Jira Cloud! So they will understand that you are dealing with a massive incident and won’t have all the answers right away. But these people are responsible for their teams and had no information to give them for over a week due to the radio silence.
Support Impacts
Another impact was that Impacted users could not submit tickets through the standard Atlassian workflow. Atlassian is somewhat famous for only allowing online ticket submissions for all but their most expensive support plans. For Cloud customers, this online form required you to log into your Atlassian ID and provide a valid Cloud URL to submit a ticket. Which…might be a problem if Atlassian accidentally deleted your Cloud URL.
Furthermore, as I mentioned earlier, the contact information for the Admins of affected Cloud Sites was also deleted as part of the process, meaning Atlassian had no way to get a hold of affected stakeholders directly. They could still reach out to the billing and technical contacts listed on my.atlassian.com, but some were outdated and no longer valid, leaving no way for Atlassian to reach out to these customers directly.
Steps Atlassian is taking to prevent another similar incident.
Soft Deletes
As a first step, Atlassian is working to implement a “soft-delete” for any delete API call. A soft delete is a method for making something unavailable without deleting it immediately from the database. This would give Atlassian some time to realize they’ve made a mistake where they could then recover the deleted data quickly.
Automate Restoration of “Multi-site, Multi-Product” delete events
Part of the overly long recovery time is that Atlassian had no automated way to recover large batches of sites quickly. To speed up the recovery of any future events, Atlassian has committed to building tooling that can handle what they now call “Multi-Site, Multi-Product” delete events. Once completed, they will include this automation in their regular DR recover drills and testing to make sure it stays operational in the future.
Improve Incident Management for Large Scale Events
Atlassian’s incident response process has worked fine for minor and major responses thus far but was inadequate for this disaster’s Scale. So Atlassian will go back to the drawing board and create a playbook and tooling to handle these large-scale incidents and conduct regular exercises to prepare people for future events.
Improve Communication Processes
This is where Atlassian thinks they failed the most, so this is where they have the most action items planned.
- They will improve how they backup key contact information so that if a site is deleted accidentally, they can still reach out to the Site Admins.
- They will retool how they take in support requests without a valid site URL or Atlassian ID to make direct contact with the support team easier.
- Atlassian is investing in a unified account-based escalation system and workflow so that customers can escalate an entire account in situations where it’s all gone wrong.
- They are adding Escalation Management coverage to allow 24/7 coverage, with designated staff based in each major geographic region.
- Update the Incident Communication Playbook with lessons learned from this event, allowing more streamlined communications of the who, what, when, where, and, once you have it, why of an event.
My Thoughts
I think I put it best to my team. I said, “Look; if I went to management and told them Jira would be out for two weeks, I wouldn’t expect to still have a job, and I don’t think that’s the wrong call.” Although I deal with only a handful of Jira instances, as opposed to hundreds, this is still not a great look for Atlassian. And this during a time when Atlassian has made it very clear that they want to see everyone on Cloud eventually.
That being said, I think Atlassian knows this and is proactively taking steps to prevent it from happening again. But, unfortunately, incident response is something of whack-a-mole. You can only cover for incidents you’ve had before and hope the next one isn’t major.
I still think having the same API call handle multiple kinds of deletion solely based on the input it received was not a great design – and had a large part in this incident. I’d like to see that separated at some point into two separate API calls, as that alone could have prevented this problem entirely.
If asked would I recommend Atlassian Cloud products, my answer is still Yes – in certain circumstances. If you are a small company, a start-up, or an individual, I think Atlassian Cloud is a great way to get started on the Atlassian platform. However, the caveat is you depend on someone else to keep your service up for you. So, if you can afford it and have a need to make sure it’s up, Data Center is the option I’d choose. If you have regulatory requirements to not be on Cloud – Data Center is the option I would choose. As it is with anything – use the right tool for the right situation.
But what do you think? Have you read the full report? What are you hoping to see out of this? Please let me know what you think in the comments!
Don’t forget; you can also find my social media links on Linktree. So please take a moment and share, comment, and like the posts – as it helps more people discover this Blog!
You can also subscribe below to receive new posts as an email. This is the fastest way to get new content from the Blog.
But until next time, my name is Rodney, asking, “Have you updated your Jira issues today?”

I wholeheartedly agree with your statement “if I went to management and told them Jira would be out for two weeks, I wouldn’t expect to still have a job, and I don’t think that’s the wrong call.”
In no way do I confidently feel that I can recommend Jira Cloud as the strategic approach for my company. If my internal Jira instance goes down then I fix it. If I can’t fix it I know that I’m going to get my arse kicked up and down the corridor; so there’s an incentive to not have it go down.
If Jira Cloud were to go down like this and I’d recommended it and had no timeline to fix and no alternative for 1000’s of developers? Well you sum it up effectively.
LikeLiked by 1 person