So, I’ve had this one request now at three different companies. We are migrating a project from a foreign Jira instance into ours, and the team using that project has some custom integration set up. This integration works against fields, so they’ve hard-set the field IDs from their Jira instance into their API calls. It’s not overly their fault; that’s how fields are referenced in the API calls.

But now that we are migrating, they are told we cannot guarantee those field IDs will stay the same in the destination. Jira sets those IDs on a first-come, first-serve basis. Whatever number is up next is what they get automatically assigned, and we as Jira Admins have as much control over that as we do the weather.
This revelation usually leads to the following discussion.
Jira Admin: I appreciate you have this integration, but you should know that the field IDs will change when we migrate.
Developer: Are you sure we can’t keep the field IDs the same? These calls are buried in our code, and it would take us too long to change them.
Jira Admin: Yes, I’m sure. It’s the luck of the draw on how Jira assigns them, and we already have way more fields than your instance, so they will be given a different number.
Developer: Have you tried asking Atlassian? I bet they have a solution.
Jira Admin: Yes, you are not the first to ask.
Manager: I’d feel much more comfortable if you asked again.
Jira Admin: ::screams internally::
Well, I both know the Database Schema reasonably well and have a test instance, so I figured I’d show you first-hand what happens when you try to change them – first to a field ID that already exists in Jira, then to one that doesn’t exist yet. Then we’ll go over what exactly happens in each case to demonstrate why it is such an incredibly bad idea.
Field IDs in Jira: a primer
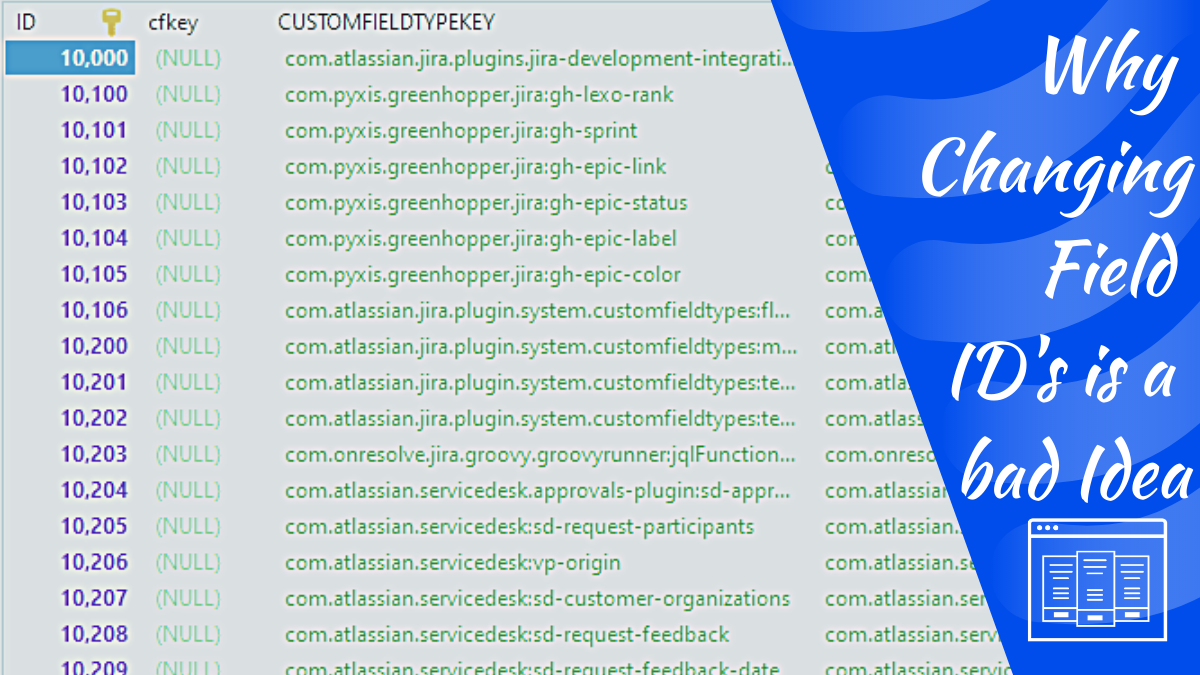
So, for those of you who don’t yet know, internally, Jira doesn’t reference fields by their name. Instead, each field is assigned a unique ID within the customfield table upon creation. This ID number is how the field is referred to anywhere else information is stored – particularly in the customfieldoption and customfieldvalues table. If we look at a sample of the data in the customfield table, we see the following.
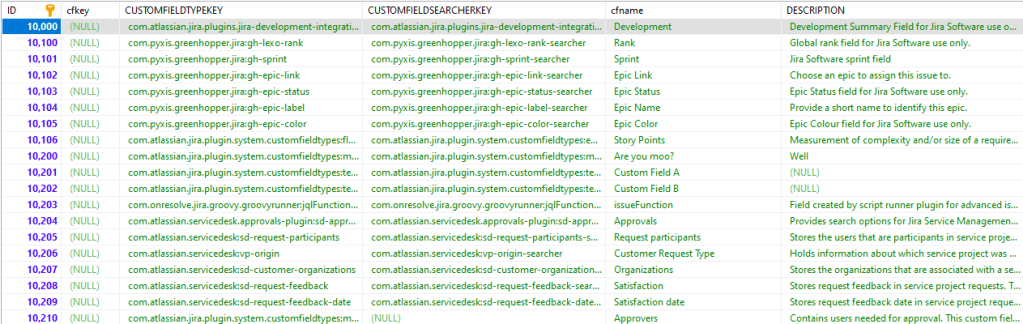
We will focus on the ID field for today’s purposes, as that is what concerns us. However, if there is an interest in the DB Schema for Jira, I am willing to dive deeper into how various things are stored within the database.
We see the ID column is marked with a key. This means that it is the table’s primary key, which comes with a few restrictions. For Example, every entry in this field MUST BE unique, and it cannot contain a NULL value. This setup is why we cannot repeat the same value for a key if it already exists in the database. If we try to update a row so that the ID is duplicated, the query will fail outright without additional steps to disable the primary key. But I’ll demonstrate that practically later in the article by trying to do so and showing you the error it generates.
IF we look at the customfieldvalues table, we can see this reference in action. This table is where Jira stores the information you put into *most* custom fields, and the data looks as follows.
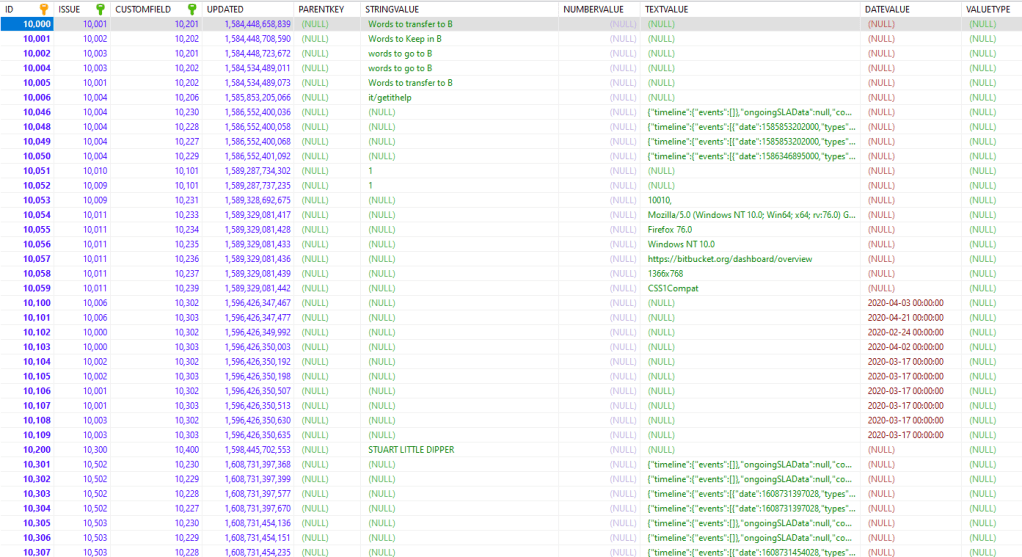
Here we see the CUSTOMFIELD column is third. If we search this ID number in the customfield table, we will find the exact field this value belongs to. Likewise, if we search for the ISSUE value from the customfield value within the ID column of the jiraissue table, we can find the issue to which each of these entries belongs. But honestly, how Jira stores issues and their data is a topic onto itself. Using these corresponding ID columns and references, Jira can dynamically assemble data on your issue.
So what happens when you change the field ID within the database?
I can’t believe I’m about to say this, but:
DO NOT try this at home. I have two layers of backups before starting this experiment. Furthermore, I’m doing this on my instance where I don’t care if I lose data. If you mess this up – which again is what I’m intentionally doing here – the only way to restore is by a DB restore, which means longer downtime.

If that wasn’t enough reason for caution, this might affect your support for Atlassian. IF they find out that you’ve made unsupported modifications to your instance such as this, they can refuse a ticket altogether. I’ve seen it happen! The last thing you want is to be in a crisis and find you no longer have support because of something like this.
That being said, here’s the plan. The first step is turning off Jira and backing up the database.
Then I’ll be finding the ID for the “Are you Moo?” field. I will first try to change it to the ID of another field with an UPDATE statement and show you the error it generates. I will also be updating all the entries in customfieldoption and customfieldvalue with this new ID number. It will give me an error on the customfield update but allow the update to the other two tables, meaning I will lose all the values stored for that field – which I will show you in Jira.
I will then restore the database and update those three tables again to a new, unused ID. I will then start Jira again and show you the issue with this – and the problem isn’t what you think it would be!
For obvious reasons, I will not be showing you the SQL Queries I will be using, but instead, show you the errors I get when I run them (if any).
TEST 1: Setting Field ID to duplicate
So for this setting, I will be taking the field ID of our target, 10200, and changing it to 10000. I will also be doing so for all three tables, even if anyone presents an error.
I get the following error upon running the change to the customfield table. MySQL sees this as a primary field and thus cannot allow duplicates.
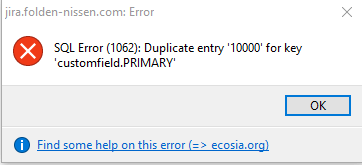
Because I can (to be clear – this is a VERY bad idea), I will disable the primary key temporarily to allow this to go through. Let’s see how jacked-up Jira can get, after all. And with that done, I start up Jira to see what it does.
After starting up Jira, the errors appear almost immediately in my dashboard gadgets. But being a good Jira Admin, I dig deeper.

Going to my system log, I see this error scrolling past repeatedly.
2022-01-12 09:11:47,806-0500 http-nio-8080-exec-8 ERROR rnissen 551x1992x1 3q5j90 192.168.1.153,192.168.3.131 /rest/extender/1.0/issueHelper/customFields/all [c.a.p.r.c.error.jersey.ThrowableExceptionMapper] Uncaught exception thrown by REST service: java.lang.IllegalArgumentException: Multiple entries with same key: 10000=Are you moo? and 10000=Development. To index multiple values under a key, use Multimaps.index.
com.atlassian.cache.CacheException: java.lang.IllegalArgumentException: Multiple entries with same key: 10000=Are you moo? and 10000=Development. To index multiple values under a key, use Multimaps.index.So – Custom fields no longer work anywhere because of this duplicate key. And considering that is one of the primary features of Jira, This instance is pretty useless until I restore the database.
But that’s just the worst-case scenario. Let’s see what happens when I change it to an unused key.
TEST 2: Setting Field ID to something unused
So, after restoring to my backup, we will try instead to change the field ID from 10200 to 10905, which is the first unused field ID. Again, I will only change the customfield, customfieldoption, and customfieldvalue tables and touch nothing else in the database.
This time my queries run without me needing to fiddle with the primary key, as I’m changing it to a unique value. So we start up Jira to see how it likes this change.


At first, everything seems good. The pie chart works, and I can see custom fields in the admin area. That is until I notice this…

Okay, your contexts, screens, and projects are no longer linked to “Are you Moo?” because they are all still looking for custom field 10200, which no longer exists thanks to our meddling. Alright, so we change customfield_10200 to customfield_10905 in the configurationcontext table, restart Jira and reload the page…and no change.
Okay, maybe we just need a reindex.
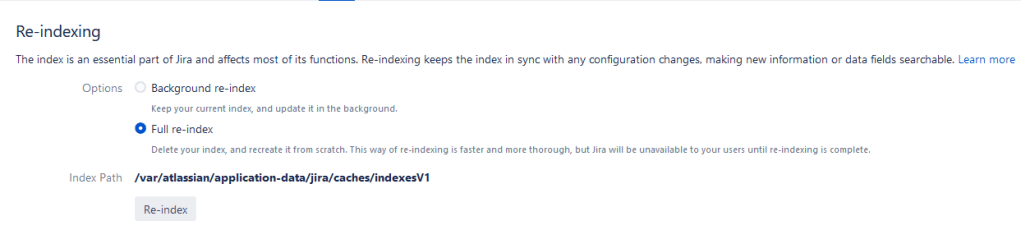
And still no change. Look, we can keep hunting in the database and updating values where we find them. Maybe we will find all the references to the old field and get them updated, but chances are we won’t. And that’s the real problem – the Jira database is so interconnected that changing anything so fundamental as a field’s ID causes a lot of problems with anything that ever referenced it.
Take-Aways
We could talk about this more, but it comes down to one question at the end of the day. Will the find-and-replace in someone’s code for hard-set values (that, let’s be honest, should have been variables to start with) be more or less risky than this process? You have to schedule a change control, bring Jira down, make unsupported direct DB changes, bring it back up, find any problems, bring it down and make more (again, unsupported) DB changes and bring it back up. And you will still likely have problems by the time you are done. And that’s if you don’t corrupt your whole instance in the process.
No. If you get pushback on this, definitely stand your ground and let them know they need to update their integrations. IF they still push, send them this post to show how bad it can get!
Final Thoughts
What are some of the unreasonable or impossible requests you’ve gotten as a Jira Admin? Let me hear about it! You can find all my social media links on Linktree. I love hearing from everyone, especially if you find a blog especially helpful!
Don’t forget you can also support me directly if you find the blog especially helpful. You can either give a one-time donation via the “Buy me coffee” button on Linktree, or sign up for my Patreon!
You can also sign up below to receive new posts directly to your email. This is the best way to keep up to date with the blog, so I encourage it!
But until next time, my name is Rodney, asking, “Have you updated your Jira issues today?”
Discover more from The Jira Guy
Subscribe to get the latest posts sent to your email.

We had a team that was not happy with the speed at which we updated jira, they petitioned to stand up their own instance and bosses ok’d it with a provision that once they go rogue, they cant be brought back into our main jira. All good for 2 years until their main admin quit and now they want back in to prod jira. We remind them of our agreement, they go up the chain of command. We spend a year trying to get their data back in and finally gave up. Configuration manager for jira does a fairly good job of exporting/importing but your old field IDs are are a show stopper you just have to live with. Good article.
LikeLike