
So, let me set the scene. It’s Monday morning. You had a good weekend – yeah, it could have been longer, but it wasn’t bad by any definition. As you come in, some VP approaches you. He shows you his phone, which has Jira pulled up with the following message.
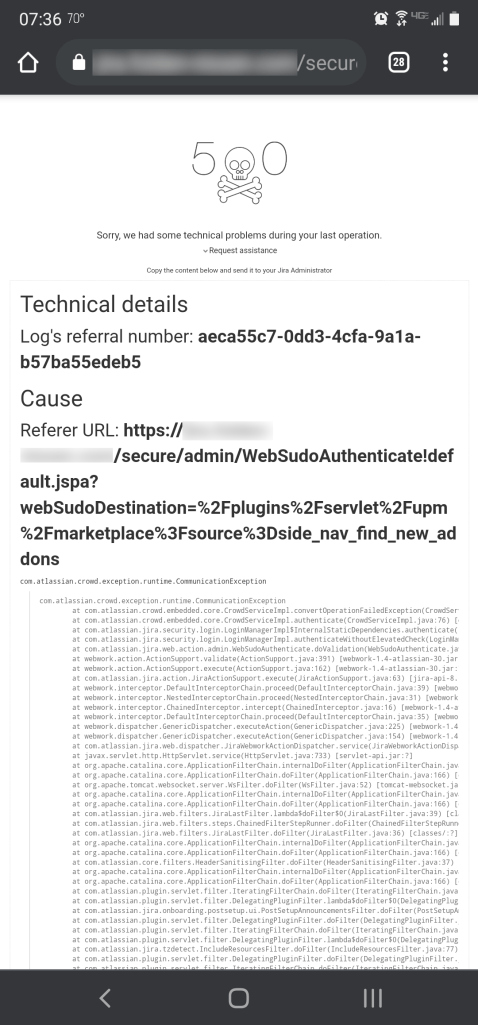
Well, there goes your morning. He’s high enough you can’t ignore it as a one-time deal, and you have to investigate that. But where do you start? How do you go from an obscure (and some would say cryptic) 500 Error to the actual root cause and solution? That’s what we’ll be going over today!
Fortunately for me, this isn’t the situation I’m facing. This image is from my personal test server. We had a power outage in the community yesterday that lasted about three hours or so, and as the UPS on the servers only has enough charge to last about 15 minutes at the current load – yeah, the servers went dark. So when I went to check if everything came back up, I got this error. But it seemed like a good thing to go over; so, let’s dig into this!
Step One: Is this easily replicable?
I have a theory that if you can know every factor involved, down to the quantum level, every bug is reproducible. However, computers are inherently quantum machines, which means it’s impossible to know every factor. It could be that if you access Jira with this specific client at the same time that someone else accesses Jira with a different specific client, this happens. It may sound a bit extreme, but I’ve seen bugs that looked like that before.
So the question becomes can you replicate it with the knowable factors. To do this, I usually first ask the user how often they’ve seen this problem. Is it something that shows up every time for them, or is this the first time they’ve seen it? This answer will be your clue to how easily reproducible the bug is. If they say it’s the first time they’ve seen it, take a screenshot of the error (so you have it), and ask them to try it again. If, however, they’ve said this is something they often do, and it’s something that only pops up occasionally, well, you’ve got an “intermittent” problem, and you’re in for a bad time.
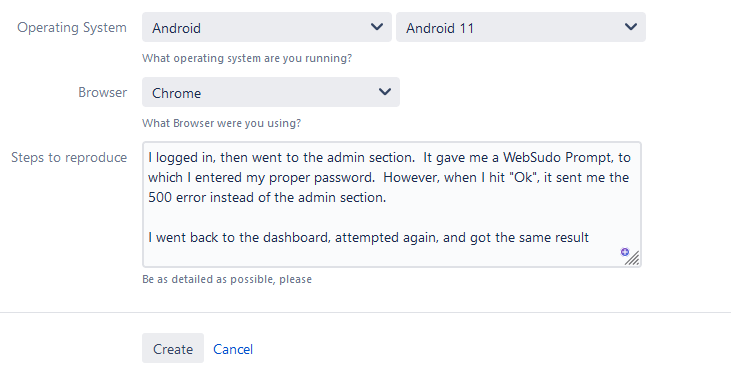
Now that we know that detail, we need to gather as many details as possible. Ask them EXACTLY what they were doing leading up to the error, what username they were using, what browser and OS they were on, has this error been seen on other browsers or operating systems. These details will help us identify where the problem might lie, so there is no such thing as too many details.
Step Two: Reproduce the Bug for yourself.
Let me be clear: if you can reproduce this bug on-demand, you will have a MUCH easier time resolving it than if you have to depend on the user to reproduce it for you. Conventional wisdom usually states that you should mimic the user’s environment as closely as possible first, then deviate as you explore the problem. That’s bull.
I prefer to try to replicate the bug on my typical setup first and then get closer to the user’s configuration as I rule things out. If you can reproduce it on a different browser and OS, you can automatically rule those things out as the cause. Can you reproduce it with your user? Then it’s something both users have in common.
In my case, I initially encountered this using my regular username on Chrome running on Android. So I tried it on the same user running on Firefox/Windows, to the same error. So I know it’s not OS or Browser related. I then tried my backup Admin account, which worked as expected. That should be a lightbulb moment. Whatever is causing this error, it’s something that doesn’t apply to the other user.
Step Three: Analyze the Error in detail
So, we can reproduce the bug pretty much at will, and we know it’s something to do with the user. Now what? Well, Jira gave you an error message; let’s look at it!
Some would say that this should come before trying to reproduce the bug. I have to disagree. It’s always important to test whether a bug is solved before handing it back to the user. And if you don’t test it before, how do you know whether it’s solved or just not reproducible by you? That’s why you should look to test it out first, then start trying to fix it.
Be aware this might mean you have to go onto the system logs as well. You can find these in Jira’s Home directory, under the log folder. The main one you will want to look at is atlassian-jira.log.
Honestly, most of the code listed in my error is still Greek to me. However, going through line by line, I did notice something that stood out to me. I came across this “Caused By” line most of the way down the page that seemed to point directly to the problem.
Caused by: org.springframework.ldap.CommunicationException: nas.<redacted>:389; nested exception is javax.naming.CommunicationException: nas.<redacted>:389 [Root exception is java.net.NoRouteToHostException: No route to host (Host unreachable)]
So this request failed because Jira could not reach this NAS system. This error naturally segues into my next step, which is…
Step Four: Has anything changed recently?
So, we can reproduce the bug, and in doing so, we have identified it as something to do with the user itself. We then looked at the error code, which said it also had something to do with this NAS system. Next step, we need to figure out and document if anything in the environment has changed recently. This exercise may take both time and your detective skills to figure out, as the problem may lie well beyond Jira itself. For problems that weren’t there before and are present now: Something must have been the catalyst for this new behavior.
In this case, it was easy. I had recently decommissioned a small Network Attached Storage from my network, figuring I’d find the few services that still referenced it over the next few days and set them up. One detail I forgot, though – I was also using the NAS as the LDAP server that Jira happened to be referencing.
This would explain why one user was affected and another not so. The affected user belongs to the LDAP directory, while the unaffected one is a part of the local directory. It also explains the message in the Error Code. The box was unreachable because it’s been shut down.
So, how was I able to authenticate and login if the Authentication method was shut down? Well, that’s because I am using a SAML SSO provider to handle my authentication (side Shoutout to Resolution!). Because this handled authentication, there wasn’t a need to worry about checking the password until I went to do a websudo.
However, this is a relatively straightforward case, and I was able to find a solution quickly. What happens if you get this far and still haven’t found anything?
Step Five: Research
So you’ve got a fair bit of information now, take your time and do some research with the details you have. Google the error message itself or the “Caused By” line. You don’t want to go to Support when the answer was the first entry on a Search Engine. See if anyone else has seen this issue and just not reported it. Having more details from more users might help you identify the issue. It’s a small step, but you have the collective human knowledge of lifetimes sitting there and already indexed. Use it!
Step Six: Get some Support
It will happen that at some point, you will get here and still be stuck. The good news is if you have an Active Support license, you are not alone! I, in general, have had some pretty good experiences with Atlassian Support over the years. They are a resource available to you, so don’t forget that.
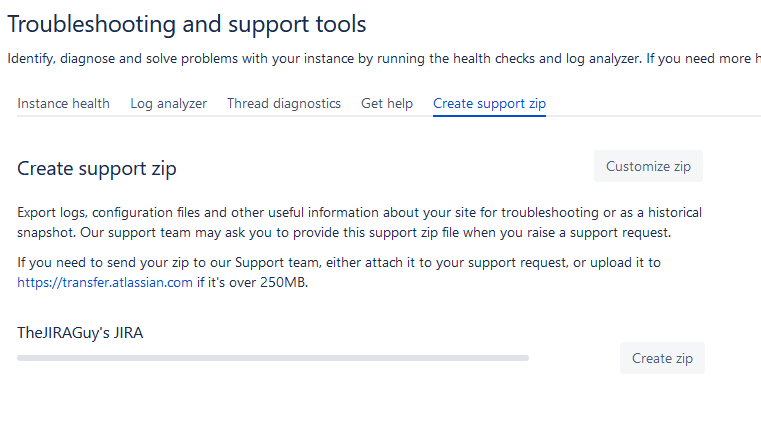
To get started, you will need to generate what’s called a “Support Zip”. This file is a sanitized collection of various settings in your instance and some recent logs. I like to have the user reproduce the issue (or reproduce it myself if possible), then run the routine to collect the Support Zip.
You can find this in the Admin Section (<<Gear Icon from last week>>) -> System -> Troubleshooting and support tools -> Create Support Zip. If you are running on a Data Center environment, be sure to run it on the node the user experienced the problem on.
So then what? Well, go to Atlassian Support, enter all the relevant information you have collected, including the support zip, then provide them with any more details they require. They will then work with you to investigate the issue and provide a solution. Be patient. If it’s related to an App, they can usually point you in the right direction from there. But Honestly, if you’ve gotten this far, this is your best hope for a solution, so stick with it.
I hope this helps you!
I know I’ve been in this situation a fair bit over my career. If you get a Jira instance with any scale, it’s likely to develop some problems with time. As long as you have a plan when it happens, you should come out the other side relatively intact.
So, here we are, the last day of June. It seems to have gone by in a hurry. Right now, we are right around 5,730 page views for the month, compared to last month’s 5,910. I want to see if you can get that number up past last month’s! To do that, I want everyone to find an article that they think a colleague could benefit from and share it with that colleague! Let’s see if we can grow this little community that much more!
Don’t forget you can also follow the blog directly to get new posts directly to your inbox. It’s the fastest way to get new content. You can also follow The Jira Guy on Facebook, LinkedIn, Instagram, or Twitter. There you can get the latest news, updates on the blog, or just juicy memes I borrow from other Atlassian Experts. But until Next time, my name is Rodney, asking, “Have you updated your Jira issues today?”

Subscribe to get new posts by email!
Discover more from The Jira Guy
Subscribe to get the latest posts sent to your email.
