
Well, we made it to August! I hope you enjoyed App Month. To be completely honest, I only realized July had five Wednesdays after I had already committed to the idea. Oops!
But I got to meet some really great Atlassian Partners, learn some cool things about some Apps, and in general had a lot of fun. And you guys seemed to like it too!
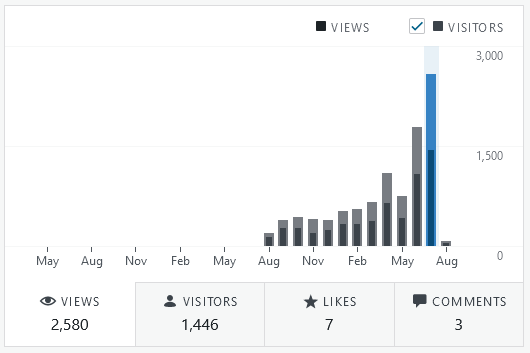
Another record breaking month, with an additional 800 page views on top of June. To put it mildly, you guys killed it! Let’s see what August holds!
Today we will be looking at what you should do when Jira is down. As usual with us, this only applies to Jira Server and Data Center. Look, no matter what we do, Jira will come down unexpectedly at some point. That’s just one of the joys of running any service. If you are lucky and are monitoring all the right metrics, it may only come down when you plan for it to. However, everyone’s luck runs out at some point. So lets take a look at what we can do now to be prepared.
Have a Plan
There was a time, early in my career, where I didn’t plan for downtime. When downtime happened, I was all panic, no purpose. I’d extend downtimes longer than they needed to be so that I can find a permanent solution. This ladies and gentlemen is an inadequate approach when people depend on your system.
When people depend on your system to do their work, every hour it’s down is an hour the company is paying them to do nothing. I once had to break it down like this for a software engineer who wanted me to keep Jira down until lunch.
Let us say you have 400 Developers, with an average salary of $150,000/yr. That breaks down to roughly $72 per hour per Developer. That means a Jira outage cost you $28,846 in lost productivity every hour, and that is just Developers! It does not include Project Managers, IT, Management, UI/UX, QA, and everyone else that depends on Jira. You can see how it can quickly add up.

However, it is possible to be too hasty here too. You could be destroying information you need for a permanent fix by performing a quick fix. In that situation, you’ll likely have a ticking time-bomb, ready to bring down your system again.
That is why it is essential that you have a plan. Ideally, a document that describes whom to contact, what information to gather, and when to escalate. The industry term for this document is a Runbook, and it is recommended you have one for every system you manage.
In the past, I’ve linked to a generic Runbook template – and to be honest, it wasn’t the greatest for Atlassian Products. Atlassian themselves have a template that I like better than the one I’ve previously linked. However, I’ve taken the time to customize it further into a generic Jira Runbook template. This request came out of my last Webinar, and I thought it was a great idea! It will still need a lot of information specific to your instance filled in, but at least it’s a start!
Communicate Immediately
So, you’ve got a plan, and you’re following it. Good. But remember, many people need Jira and can’t get to it. Keeping them in the dark only means dealing with that many more interruptions while you try to fix things. They need to know what’s going on, even if the single update is “I know about it, I’m working on it, and I’ll give up updates as I know more.”
There are several ways you can do this. I had a list of email groups in Outlook that I could copy/paste into a new email. This method meant I didn’t have to remember who all I needed to contact – as again, I usually had other things on my mind. I just wrote up my message, pasted in the BCC, and hit send.
<pet-peeve> By the way, that’s another thing. For large chains, use the BCC rather than CC or TO lines. That way, if anyone needs to reply to you, they can without interrupting everyone else. </pet-peeve>
Another option you can look at is Statuspage. I’ve always liked the product, even though I never had the benefit of working with a group that used it. Training your users to check here for issues will help them find information on outages first without bothering you. Doing this sounds like a win-win to me.
Collect Information
So, you’re following your plan, and you’ve notified your users. Next?
Next, you need to take time now to gather information before attempting a restart. Typically, I like to have the following two things in case I need to go to support.
1: Thread Dump
A thread dump is a detailed list of everything Jira is doing currently and how long each task is taking. Having these details can be invaluable in determining why Jira is behaving weirdly or being slow. Atlassian provides a script now to automate capturing these thread dumps. Check out the docs on Thread Dumps here:
As a note on Thread Dumps, if you install a plugin called Thready, it will help you analyze the thread dumps by attaching the thread’s name to each entry. It’s a free plugin and doesn’t impact performance, so I usually test and install it on my instances to be ready.
2: Support Packet
The support packet is another thing I try to capture if I can. Getting this will depend on your Jira instance being alive and responsive, so you may not be able to get it. If you can’t, don’t worry. Capture your log files from <Jira Home>/log/*.log, and you should be good to go. But the idea is before you try to change anything to get Jira back up, take a moment to get things that will help you solve this problem long-term.
Try to change one thing at a time.
So, you’ve collected the evidence, and you’ve told people you’re on it. What now? You can run in like a firefighter, make eleven changes, and pray one of them fixes Jira, right?
WRONG! Look, you’ll want to tell your management, your users, and your future self what went wrong and how you fixed it. You can’t do that if you aren’t sure what fixed the problem. That is why you need to take a breath, calm yourself, and focus on one change at a time. Change something; see if it works now. Change again, repeat. Do so until something works. You will still need to pay attention to the logs and hunt for clues on google. But take your time, and be methodical, and be sure what your problem was when all is said and done. You will be thankful for it; trust me.
Did I say Communicate?
Congratulations, you’ve gotten through the worst part of it. Jira is now back up and running, and everyone’s happy, right?
Well, no. First thing, you need to let your users know Jira is back up and ready for use. They are waiting to do their jobs, after all. Some of them will find it’s working on your own. But it is common courtesy to let everyone know.
Document, document, document!
For some, this will be the worse part. It’s excellent Jira’s up and running, but some people (like your management) may have questions about what happened. And these are not people you want to keep in the dark.
I typically write a document that I call an After Action Report. I’ve also heard them called Root Cause Analysis, but and After Action Report makes me feel more like a hero after a big fight. Yes, it’s an ego thing.
Typically, I’m looking to answer three questions:
- What went wrong. Include a timeline of events, and the major players and systems involved.
- What you did to fix it short term. Be detailed, and write down procedures and commands. You never know when having these handy will save you time in the future.
- How you intend to keep this from happening again. Action items here could either be permanent fixes to be done, a followup with Atlassian support, monitoring on a specific metric or component, or a change to Standard Operating Procedures. The idea is to show you intend not to let a problem become a pattern.
Keep these in the same place (Confluence!). Again, if you’ve done your job right, you may never have to reuse one. But it’s handy to have it there and helpful if you ever need to refer to a fix you’ve found before.
Congratulations, you’ve survived!
Having downtime can be one of the most stressful events of your career. I should recount the time I was on duty for twenty-four hours straight with a severely troubled Jira instance. To be fair, I only spotted the problem after taking three hours to get some rest – so had I gotten some rest sooner, I may have resolved it that much faster. Seriously, don’t be me!
What are some of your downtime stories? I’d like to hear some of them in the comments! In speaking of comments, next week I’ll be compiling all the questions I’ve gotten in the comments and on DM’s into a post! If you have any questions you’d like me to answer, go ahead and get them in!
If you’ve enjoyed this post, be sure to follow the blog to get new posts directly in your inbox! You can use the form below to sign up! You can also follow us on Facebook, Twitter, and LinkedIn to get the latest updates! Be sure to like and comment on the posts, so the social media networks know the Jira Guy is worth sharing! But until next time, my name is Rodney, asking, “Have you updated your Jira issues today?”
Discover more from The Jira Guy
Subscribe to get the latest posts sent to your email.
