Hello everyone! How has your week been going? This week we are going to talk about JQL – and honestly, I’m not entirely sure how this hasn’t come up already. I know I’ve provided a few queries here and there to help you in other topics, but today I’ll be talking about some of my favorite tips and tricks to get the most out of your queries. So without any more delays, let’s get into it.
Always about the Docs
So it’s been a while since I’ve included this section – but I feel this subject could be helped with some further reading. So for this, I am referencing two documents:
I should note that the function reference is for JIRA Cloud – so it does have some new functions that have not made it to server. However, the options I’m covering here will work for JIRA Cloud, JIRA Server, and JIRA Data Center.
Currentuser()

So, this first trick is one of my favorites, as it allows you to customize a query to be specific for whoever is viewing it. In your query, you can set a user field equal to currentuser(), and the function will return whoever is logged in and viewing the query. For example, let’s take the query:
assignee = currentuser()And let us take a look at what that looks like when running from the Admin account, and my account:
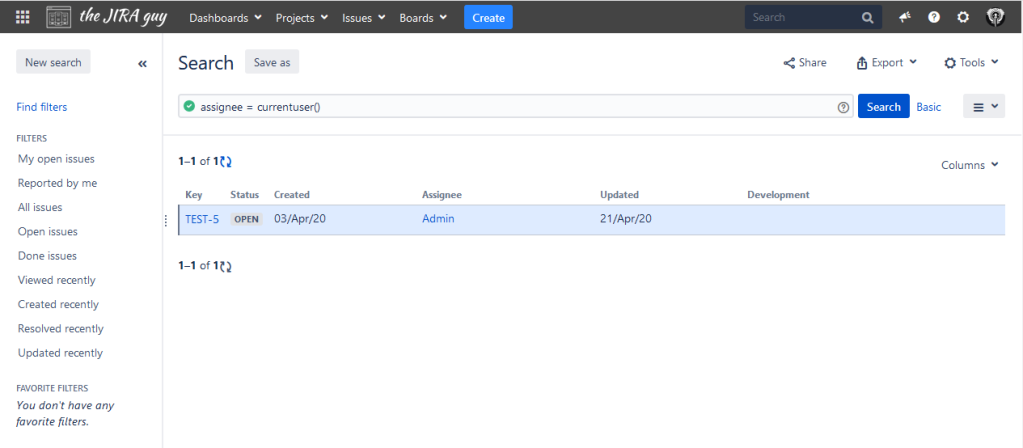
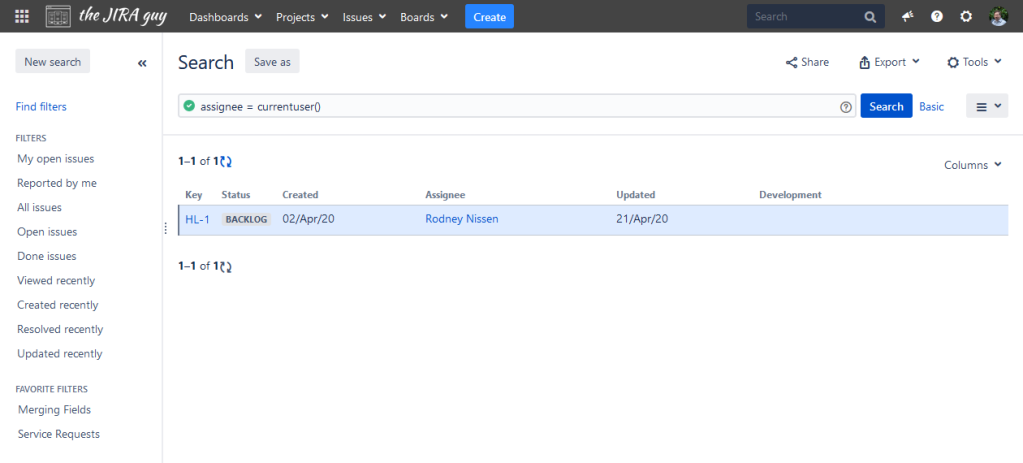
Each one returns whatever is assigned to the specific user. What’s more, this would carry over to any dashboard that uses this query – allowing you to customize a single dashboard to whoever views it.
This also works with any user field: reporter, assignee, watcher – and even custom fields. This is a handy trick to have if you don’t like to spend your day making queries and dashboards…I mean, who would enjoy that, am I right…

Working with time
So, when I’m giving some training for JQL, the most common problem people have is working with time. “How do I search for stuff in the past?” “How do I work with time?”…it seems to be a challenge.
Here’s a trick that’s always helped me. Most databases store time in the Unix Epoch time format – which is simply counting the seconds between midnight of 1 Jan 1970 and today. This means that any time in the past will be less than the current time, and any time greater than now will be in the future. Same for JQL. The past is “less than” the timestamp you are looking at, and the future is “greater than”.
However, JIRA also gives us some handy functions so we are not having to spell out particular date. First off is now(), which simply returns the current timestamp whenever it’s run. Handy when just trying to find out what’s past due, such as in this example (courtesy Atlassian):
duedate < now() and status not in (closed, resolved)In the above query, duedate < now() returns everything that has a duedate in the past, and status not in (closed, resolved) returns everything that is currently open – giving you an idea what is past-due.
| Day | Week | Month | Year | |
|---|---|---|---|---|
| starting | startOfDay() | startofWeek() | startaOfMonth() | startOfYear() |
| ending | endOfDay() | endOfWeek() | endOfMonth() | endOfYear() |
These are great for establishing a time frame. The really powerful thing about the functions on this table is they take parameters, meaning you can adjust them forward and backward – to say find all the issues resolved last month:
resolutiondate > startOfMonth(-1) AND resolutiondate < endOfMonth(-1) In this query, we shift both startOfMonth() and endOfMonth() by -1. The minus (-) tells us it’s a previous time, and the one (1) tells us to shift one whole month, meaning both of these times return values for the previous calendar month. This gives us a handy time-box for our queries – which is great for a report.
Sprints and Versions
So, this section is for my JIRA Software teams out there.
When I’m a part of Agile teams, I like to have a dashboard we can all view that tells us what’s going on in the current sprint. For this, we can use the opensprints() function. I like to pair this with a project key query so that I only get the open sprint for my project, such as:
Project = "Project Name" and Sprint in openSprints()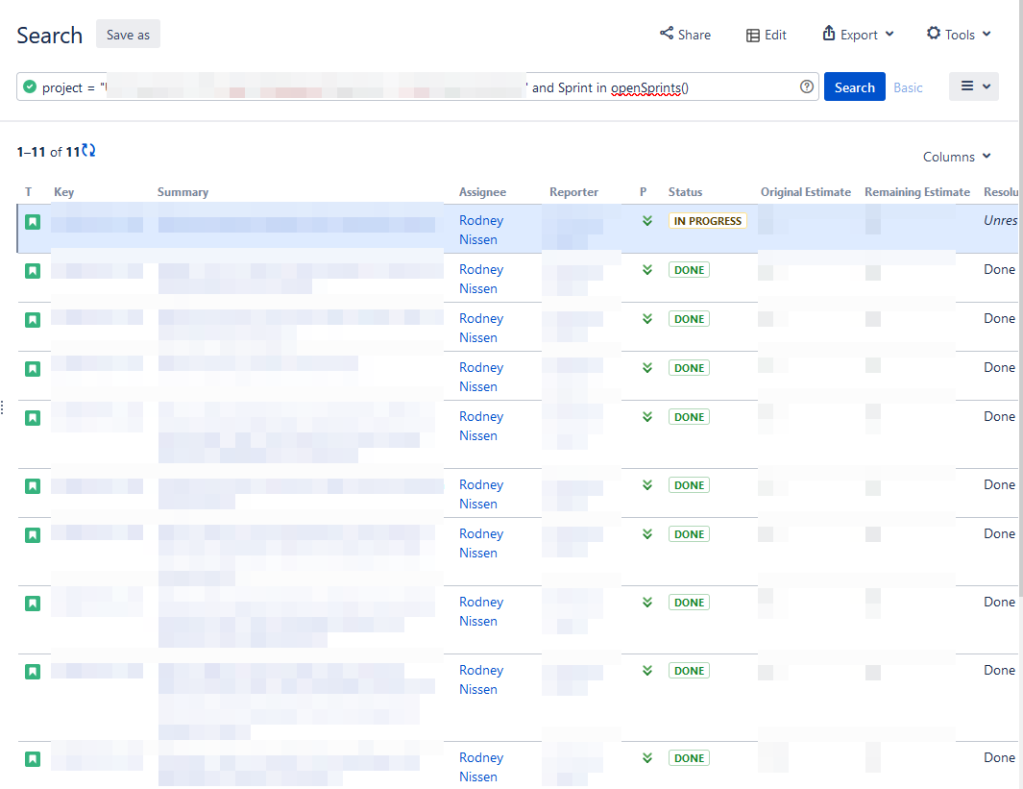
A note on openSprints() is that it only supports the operators IN and NOT IN. Using an equal sign will cause the query to return an error.
There is also the operators futureSprints() and closedSprints(). However, these return ALL future and closed sprints, respectively, so further filtering will be needed to focus on any particular sprint (such as Sprint = “Name”)
So, let us say you are in a situation where you care more about what has and hasn’t been released than what is in any particular sprint. Then you’ll be interested in the functions latestReleasedVersions() and earliestUnreleasedVersions(). These operate on the fields AffectedVersion, FixVersion, as well as any custom fields with type Version. Let’s say you want to know what bug-fixes have gone out the door:
issuetype = Bug and fixVersion = latestReleasedVersion()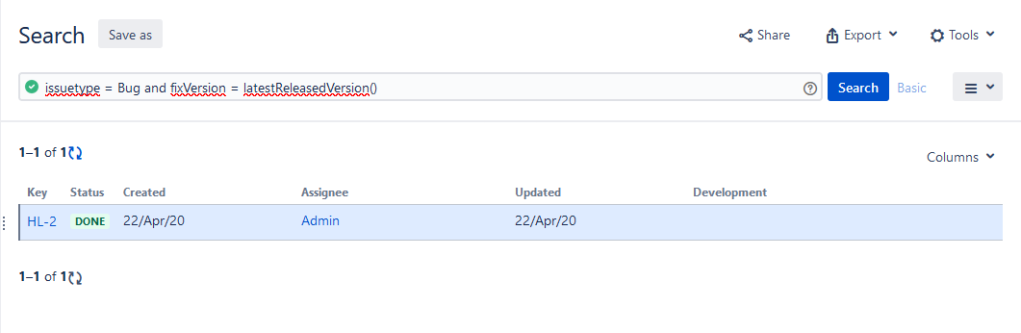
The neat trick about this query is that it will automatically update if your team releases a new version, meaning if you use it in a dashboard, it will always show the bugs fixed in the last released version.
Filtering out sub-tasks
So this one comes up often. A manager wants a dashboard, but they don’t want to get bogged down in the minutia of the sub-tasks. This a handy trick I use to filter out all sub-tasks from a query. I simply and the existing query with this clause:
issuetype not in subtaskIssueTypes()
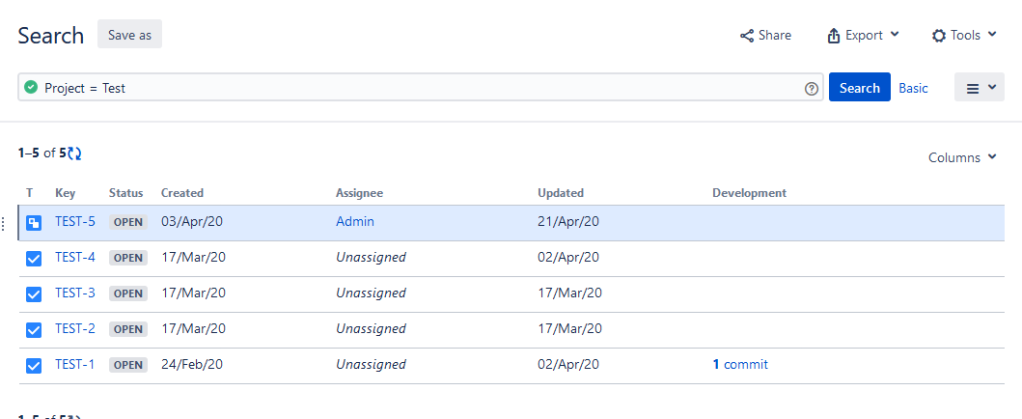
Before filtering out Sub-tasks 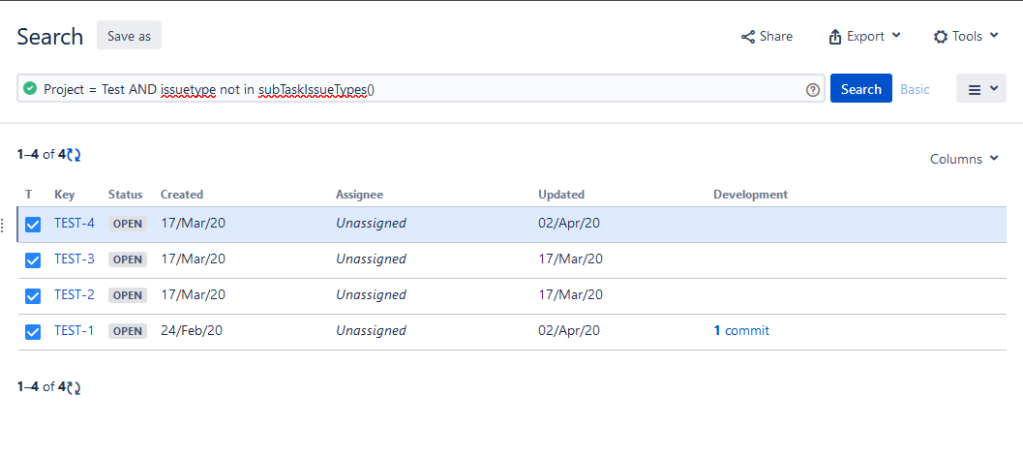
After filtering out Sub-tasks
It’s a simple thing to add but is an easy way to filter out all sub-tasks. Because of how it works, if you add any new sub-task types to the project in the future, the filter will still work without needing to be updated.
Cleaning up watched issues
So, JIRA in its current form sends out A LOT of emails.

Atlassian has heard our cries, and they are working on it, but in the meantime – this is where we are. And as an Admin, you will be touching a lot of issues – which will put you on their watchers list automatically. So I find it helpful to run this JQL and clean things up every few months.
watcher = currentuser() and project not in ("Home Project A", "Home Project B", ...)This gives me a list of all issues I’m watching on an instance that is outside of what I consider to be my “Home Projects” I use to organize my work. From there you can run a bulk change on the list, and on Step 2, choose the “Stop Watching Issues” operation. I don’t know if this honestly counts as a JQL trick, but it has helped keep me sane many a time.
And that’s all for this time!
Did you learn anything new? What are some of your favorite JQL tricks that I didn’t cover? If I get enough I’ll do a part 2 to this!
So it’s been a busy time for me. I decided to take advantage of the current time I have to study for my next ACP exam. It’s scheduled for May 8th, which doesn’t give me too much study time left. But hopefully, I’ll be sending out good news the following week!
My Wife and I also have been working on 3D printing face-shields for first responders – you can read about our efforts (okay, mostly her efforts) on her blog here: https://cadstories.com/2020/04/17/engineering-and-covid-19/
I also have a twitter account for the blog now! If that’s your preferred source of Social Media, give me a follow! I’ll be posting blog posts there, as well as anything else Atlassian related I find interesting! https://twitter.com/theJIRAguy You can also sign up here to get an email every time I publish a new blog post! Simply use the sign-up form at the bottom of this post!
Until next time though, this is Rodney, asking “Have you updated your JIRA Issues today?”

Oh thanks for a summary!
LikeLiked by 1 person
Can you help me with creating a query for all issues from a certain sprint onward? Right now I have to update the query for every new sprint.
project = AND Sprint in (488, 498, 482, 491, 502)
Any ideas? Thanks in advance.
LikeLike
I think I have an answer, if I understand your question correctly.
If you are only looking for the current sprint onwards, you can do so with “sprint not in closedSprints()”
If you are only looking for all sprints after the current sprint, you can use “sprint in futureSprints()”
However, if you are looking for something llke “give me all sprints starting two sprints in the future” – I’m afraid this can’t be done currently in JQL.
LikeLike
Thank you for the quick response!
LikeLike
Hi Rodney,
Thank you for awesome content. My management is weird and they want a very detailed report on daily basis.
This is how they want the report
Row1 Story – – title, status
Row2 Subtask1 of row1 – – title, status
Row3 Subtask2 of row2
Row4 Story2
Row5 subtaks of story2
And so on.. Problem is I tried using parent id but its not helping as they are not close.
Could you please help me?
LikeLike
Priyesh,
Let me start by saying, I know a good bit about Jira, but I am not all-knowing. So, I might be wrong, but…
To my knowledge, there is no way to sort issues as you require in default Jira. However, I did a quick test on BigGantt. It looks like with some configuration (you have to set up some structure within the Gantt Chart), it will do the report how you need.
https://marketplace.atlassian.com/apps/1213016/biggantt-gantt-chart-for-jira?hosting=server&tab=overview
Hope this helps!
Rodney
LikeLike
Hi
I would like to generate some stats on N + 1 refinement. Can I use Opensprint() + 1 in a query?
Thanks
LikeLike
No – Opensprints is just the currently open sprints.
However, you might be able to use futureSprints() – so long as you only have one future sprint created at a time.
https://support.atlassian.com/jira-software-cloud/docs/advanced-search-reference-jql-functions/#Advancedsearchingfunctionsreference-futureSprints
LikeLike