Atlassian released their April Security bulletin yesterday. Let’s dig into this, see what all the excitement is about, and see what people are getting wrong about it. Are you impacted by this?

Your weekly source for tips, tricks, and how-to's to get the most from your Atlassian tools
Atlassian released their April Security bulletin yesterday. Let’s dig into this, see what all the excitement is about, and see what people are getting wrong about it. Are you impacted by this?

Today, we look at a user-requested topic and discuss how you should name objects in Jira. Ever wonder how you can trace a screen or workflow back to a project without an audit? It’s all in how you name it! What are some of your naming rules?

Why should you even pick Jira? Today I discuss why it is a better platform, as well as prepare you to deal with the naysayers. Why did you pick Jira?

Last night, Atlassian released four new security advisories covering many of their projects. What versions are impacted, and what should you do to protect yourself? We’ll cover all that and more today!

Ever wonder what the difference is between Jira Software or Service Management, or why Jira Work Management exists? What even is JPD? Today we go over all of that and more! What’s your favorite flavor of Jira?
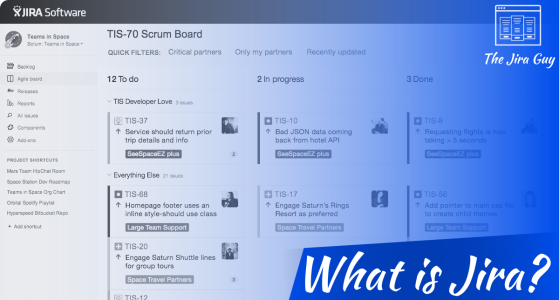
Are you new to Jira, and not even sure how to pronounce it, let alone what it is? Then join in for first post in a series meant to bring you from Jira newbie to Jira Guy or Gal!

How do you decide when to do a Jira Restart? Are regular restarts even necessary? Today we look at just that and answer a reader’s question! How do you plan your Jira restarts?

Today I discuss why I use GitLab, and why someone would want to use both GitLab and Bitbucket Cloud. What toolchain are you using?

Did you know about the #AtlassianCreators? This is a new pilot program from Atlassian to support the community creating content for Atlassian Admins and Users. Today I share a few Atlassian Creators you might want to know about! Who are you following?

This week and answer some more questions from readers who want help on where to learn and how to progress their career. What are your answers to their questions?
