Well, seems we are back on track. Last time we looked at logging, we went over how to decode the information that was in the logs. During that piece, I made the following claim:
If you set everything to Debug before you leave on Friday, by the time you are sitting down for dinner on Saturday, you’re going to be paged for a full disk.
Following the Breadcrumbs: Decoding JIRA’s Logs, 30 Oct, 2019
Well, this got me to thinking….exactly how much does JIRA’s logging level impact log size. To figure this out, we need a bit of SCIENCE!

Ze Experiment!
So here’s what I’m thinking. We take a normal JIRA instance, and we do a set number of tasks in there, roll over the logs, then see what size they are. Rinse and Repeat per log level.
So the list of tasks I have for each iteration is:
- Roll Over the Logs
- Logout
- Log in
- Create Issue
- Comment on Issue
- Close Issue
- Search for closed issue
- Log into the Admin Console
- Run Directory Sync
- Roll Logs
Between the last Roll over and the first one of the next iteration is when I’ll capture log size and adjust the logging levels.
Now to have as much of an apples to apples comparison, I’ll need to limit the background tasks as much as possible. The biggest one I can think of is the automated directory sync, which will need to be disabled for the test. However, as this is a regular activity within JIRA, I’ll be including a manual directory sync to capture that into the data set.
I’ll also need a control to measure what JIRA does by default, but that will be my first run. To make sure I can return to defaults later, I’ll be adjusting the logging levels in Administration -> System -> Logging and Profiling. Changes to the logging level here do not persist over a restart, so this should be ideal. So, without further adieu, See you on the other side.
The Results
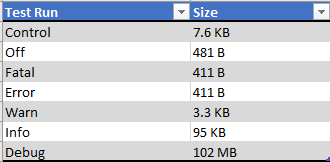
Well, That was an adventure. I ended up taking a backup of the log4j.properties file and changing it. Turns out changing > 110 settings by hand one at a time is not very time-efficient. Changing the log4j.properties file dropped the number that I had to change manually to ~30.
I tried to be as consistent as possible with each run. That means I had the same entries for each field on the issue I created, same comment, same click path, etc. I even goofed up my search on the control run (typed issueky instead of issuekey), and I repeated that mistake for each run afterwards.
Another note I want to make is that there was one setting I could not change. Turns out that if the com.atlassian.jira.util.log.LogMarker object is anything but Info, JIRA will crash when you go to roll over the logs. Oops!
Conclusions
I think even considering all that, my assertion still stands. This was one person doing somewhat normal JIRA tasks. With that the Debug was still almost 1000x the Info log. Fun fact, it rolled over the logs automatically four times. Now multiply that by how many people are using your instance, and how many times they will be doing these kinds of operations, over and over again. Even if they aren’t, there are automated processes like the Directory syncs that will take up log space. It will definitely add up fast.
However, I think the bigger consideration here is never take anything at face value. Yeah, I’m an expert, but even I was just parroting something I had been told about logging. Now I have the experiment and data to backup my assertion. Don’t be afraid to put things to a test. You might discover where some advice isn’t right for your environment. Or you might find out why things were said, and become that much more knowledgeable . The point is to always be learning.
So until next week, this is Rodney, asking “Have you updated your JIRA issues today?”

I hope that you won’t stop writing such interesting articles. I’m waiting for more of your content. I’m going to follow you!
LikeLike